2.1 Vectors
Under Construction
Vectors are mathematical entities characterized by both magnitude and direction. They are essential for describing physical quantities such as blood flow velocity, forces acting on joints, and features in image analysis for deep learning.
- A vector in three-dimensional space is written as: \[ \mathbf{v} = v_x \hat{i} + v_y \hat{j} + v_z \hat{k}, \] where \(\hat{i} = (1,0,0)\), \(\hat{j} = (0,1,0)\), and \(\hat{k} = (0,0,1)\) are the unit vectors along the \(x\)-, \(y\)-, and \(z\)-axes, respectively. The components \(v_x\), \(v_y\), and \(v_z\) represent the magnitude of the vector in the \(x\)-, \(y\)-, and \(z\)-directions. Vectors can describe the speed and direction of blood flow in vessels, facilitating the analysis of hemodynamics. They are also used to model forces acting on prosthetic joints or tissues, aiding in the study of biomechanics and prosthetic design.
- A vector in \(n\)-dimensional space is written as:
\[
\mathbf{x} = (x_1, x_2, x_3, \ldots, x_n),
\]
where each component \(x_j\) represents the magnitude of the vector in the \(j\)-th dimension.
When the vector \(\mathbf{x}\) represents a vectorized version of an image, \(x_j\) corresponds to the grayscale intensity of the image at the \(j\)-th pixel position. This representation is commonly used in deep learning for image processing tasks.





The \(L^2\)-norm (also called the Euclidean norm) of a vector \(\mathbf{x} = [x_1, x_2, \ldots, x_n] \in \mathbb{R}^n\) is defined as: \[ \|\mathbf{x}\|_2 = \sqrt{x_1^2 + x_2^2 + \cdots + x_n^2} = \sqrt{\sum_{i=1}^n x_i^2}. \]

- The Euclidean norm is derived from the Pythagorean theorem: for a right triangle with legs \(a\) and \(b\), and hypotenuse \(c\), it holds that: \[ c^2 = a^2 + b^2. \]
- In two dimensions (\(\mathbb{R}^2\)), the \(L^2\)-norm of a vector \(\mathbf{x} = [x_1, x_2]\) represents the length (or magnitude) of the vector. This is equivalent to the hypotenuse of a right triangle with sides \(x_1\) and \(x_2\): \[ \|\mathbf{x}\|_2 = \sqrt{x_1^2 + x_2^2}. \]
The distance between two vectors \(\mathbf{u} = (u_1, u_2, \ldots, u_n)\) and \(\mathbf{v} = (v_1, v_2, \ldots, v_n)\) in \(n\)-dimensional space is given by the Euclidean distance: \[ d(\mathbf{u}, \mathbf{v}) = \sqrt{\sum_{j=1}^n (u_j - v_j)^2}. \] Alternatively, in terms of the \(L^2\)-norm, the distance can be written as: \[ d(\mathbf{u}, \mathbf{v}) = \|\mathbf{u} - \mathbf{v}\|_2. \]
- The figure below illustrates that the direct Euclidean distance between the images of two different digits, such as 4 and 9, can sometimes be smaller than the distance between an image of a digit (e.g., 9) and its transformed version (e.g., a translated or rotated version of 9). This highlights the limitation of using direct Euclidean distance for digit classification in the MNIST dataset. In deep learning, instead of comparing raw pixel values, features are extracted from MNIST digit images, typically represented as embeddings or feature vectors (sometimes conceptualized as "barcodes"). These feature vectors capture the semantic structure of the images, and distances between these vectors are then used for robust digit identification.

- Face recognition is a challenging problem, primarily due to the difficulty in finding robust feature vectors that accurately represent face images. The complexity arises from various factors, such as changes in appearance over time, weight fluctuations, lighting conditions, facial expressions, and other variations. While technologies like the iPhone have achieved notable success in face recognition, they are not as reliable as fingerprint or iris recognition for high-security applications, which is why face recognition is not widely adopted for critical tasks such as airport security. In the example shown in the figure below, the two images are of the same person, and from a human perspective, the distance between them should be zero. However, deep learning-based encoding methods still face challenges in producing identical feature vectors for such cases. This highlights the need for more advanced techniques to improve the robustness and accuracy of face recognition systems.


The inner product (or dot product) measures the projection of one vector onto another.
- For three dimensions: \[ \mathbf{u} \cdot \mathbf{v}:= \langle \mathbf{u}, \mathbf{v} \rangle = u_x v_x + u_y v_y + u_z v_z, \] or equivalently: \[ \langle \mathbf{u}, \mathbf{v} \rangle = \|\mathbf{u}\|_2 \|\mathbf{v}\|_2 \cos\theta, \] where \(\theta\) is the angle between \(\mathbf{u}\) and \(\mathbf{v}\). Here, \(\langle \cdot, \cdot \rangle\) represents the inner product.
- The work done by a force \(\mathbf{F}\) moving an object along a displacement \(\mathbf{d}\) is given by: \[ W = \mathbf{F} \cdot \mathbf{d} = \|\mathbf{F}\|_2 \|\mathbf{d}\|_2 \cos\theta. \] This can be applied to calculate, for example, the energy required to push blood through a stenosed artery.
- For \(n\) dimensions: \[ \mathbf{x} \cdot \mathbf{x'} = \langle \mathbf{x}, \mathbf{x'} \rangle= \sum_{j=1}^n x_j x_j' \] where \(\mathbf{x}\) and \(\mathbf{x'}\) are \(n\)-dimensional vectors.
- When \(\mathbf{u}\) and \(\mathbf{v}\) represent two vectors, the dot product \(\mathbf{u} \cdot \mathbf{v}\) is a measure of their similarity. A larger value of \(\mathbf{u} \cdot \mathbf{v}\) indicates a greater degree of similarity between the two vectors. If the vectors \(\mathbf{u}\) and \(\mathbf{v}\) are normalized, the dot product simplifies to the cosine of the angle \(\theta\) between them: \[ \frac{\langle \mathbf{u}, \mathbf{v} \rangle}{\|\mathbf{u}\| \| \mathbf{v}\|} = \cos \theta, \] where \(\theta\) is the angle between \(\mathbf{u}\) and \(\mathbf{v}\). In this case, a larger dot product corresponds to a smaller angle, which indicates a higher level of alignment or similarity. This concept has practical applications in physics and engineering.
- For example, in feature space, we can represent the characteristics of a cat and a tiger as vectors \(\mathbf{u}_{\text{cat}} = [u_1, u_2, \ldots, u_n]\) and \(\mathbf{v}_{\text{tiger}} = [v_1, v_2, \ldots, v_n]\), where each component corresponds to a specific feature such as size, color, or texture. Once \(\mathbf{u}_{\text{cat}}\) and \(\mathbf{v}_{\text{tiger}}\) are constructed, their dot product is calculated as: \[ \mathbf{u}_{\text{cat}} \cdot \mathbf{v}_{\text{tiger}} = \sum_{i=1}^n u_i v_i = \|\mathbf{u}_{\text{cat}}\| \|\mathbf{v}_{\text{tiger}}\| \cos \theta, \] where \(\theta\) is the angle between the two vectors. If the vectors are aligned (\(\theta\) close to 0), the dot product is large, indicating high similarity. If the vectors are orthogonal (\(\theta = 90^\circ\)), the dot product is zero, indicating no similarity.
- The inner product of two functions \(f(t)\) and \(g(t)\), defined on the interval \([a,b]\), is
\[
\int_a^b f(t)g(t)\,dt,
\]
which can be approximated by
\[
\int_a^b f(t)g(t)\,dt \approx \sum_{j=1}^n f(t_j)g(t_j) \Delta t,
\]
where \(\Delta t = \frac{b-a}{n}\) and \(t_j = a + j\Delta t\). Hence, \(\int_a^b f(t)g(t)\,dt\) can be viewed as the inner product of two vectors
\( \mathbf{f} := (f(t_1), f(t_2), \ldots, f(t_n))\sqrt{\Delta t} \) and \(\mathbf{g} := (g(t_1), g(t_2), \ldots, g(t_n))\sqrt{\Delta t}:
\) \[
\int_a^b f(t)g(t)\,dt \approx \mathbf{f} \cdot \mathbf{g}=\langle \mathbf{f}, \mathbf{g} \rangle.
\]



The cross product of two vectors in three dimensions results in a vector perpendicular to both, defined as: \[ \mathbf{u} \times \mathbf{v} = \begin{vmatrix} \hat{i} & \hat{j} & \hat{k} \\ u_x & u_y & u_z \\ v_x & v_y & v_z \end{vmatrix}. \]

- The magnitude is: \[ \|\mathbf{u} \times \mathbf{v}\| = \|\mathbf{u}\| \|\mathbf{v}\| \sin\theta, \] where \(\theta\) is the angle between the vectors.
- The vector cross product \(\mathbf{u} \times \mathbf{v}\) is perpendicular to both \(\mathbf{u}\) and \(\mathbf{v}\).
- The cross product is used to compute torque, which describes the rotational effect of a force: \[ \mathbf{\tau} = \mathbf{r} \times \mathbf{F}, \] where \(\mathbf{r}\) is the position vector from the axis of rotation to the point of force application. Click this link for a visual explanation.
The convolution product combines two functions and is widely used in signal processing applications.
- For a one-dimensional signal, the convolution of two functions \(f(t)\) and \(w(t)\) is defined as: \[ (f * w)(t) = \int_{-\infty}^\infty f(\tau) w(t - \tau) \, d\tau. \] In deep learning, convolution can be interpreted as an inner product between a kernel (filter) and a segment of the input signal. Click this link for a visual understanding of convolution.
- For discrete signals \(\mathbf{f} = [f_1, f_2, \ldots, f_N]\) and \(\mathbf{w} = [w_1, w_2, w_3]\), the convolution at position \(k\) can be written as: \[ (\mathbf{f} * \mathbf{w})_k = \langle \mathbf{w}, \mathbf{f}_{k:k+2} \rangle, \] where \(\mathbf{f}_{k:k+2}\) denotes the segment of \(\mathbf{f}\) starting at index \(k\) and spanning 3 elements.
- For image processing, convolution is similarly defined but extended to two dimensions. Let \(\mathbf{I}\) represent the 2D input image, and \(\mathbf{w}\) represent a \(3 \times 3\) kernel (filter). The convolution at position \((x, y)\) can be expressed as:
\[
(\mathbf{I} * \mathbf{w})(x, y) = \langle \mathbf{w}, \mathbf{I}_{x:x+2, y:y+2} \rangle,
\]
where \(\mathbf{I}_{x:x+2, y:y+2}\) is the \(3 \times 3\) subregion of the image centered at position \((x, y)\), and the inner product is computed as:
\[
\langle \mathbf{w}, \mathbf{I}_{x:x+2, y:y+2} \rangle = \sum_{i=1}^3 \sum_{j=1}^3 w(i, j) I(x+i-1, y+j-1).
\]
Convolution is thus a weighted sum, calculated via the inner product, where the weights are determined by the kernel \(\mathbf{w}\).

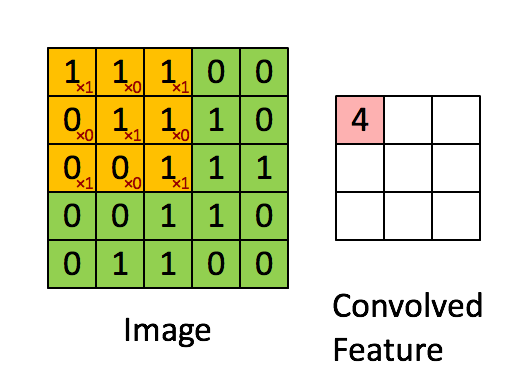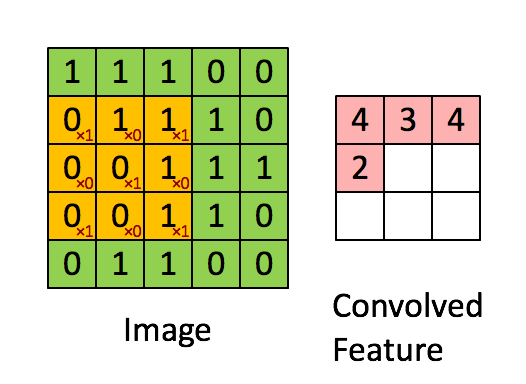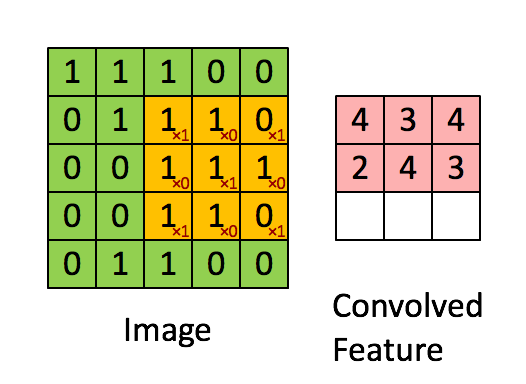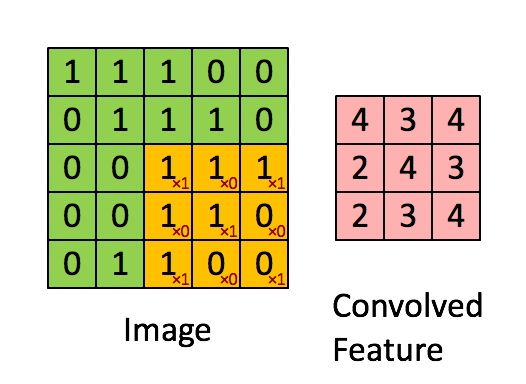
- This link shows how to compute the following convolution: \[ \underbrace{\begin{bmatrix} 1 & 1 & 1 & 0 & 0 \\ 0 & 1 & 1 & 1 & 0 \\ 0 & 0 & 1 & 1 & 1 \\ 0 & 0 & 1 & 1 & 0 \\ 0 & 1 & 1 & 0 & 0 \end{bmatrix}}_{\mathbf{I}} * \underbrace{\begin{bmatrix} 1 & 0 & 1 \\ 0 & 1 & 0 \\ 1 & 0 & 1 \end{bmatrix}}_{\mathbf{w}} = \begin{bmatrix} 4 & 3 & 4 \\ 4 & 4 & 3 \\ 2 & 3 & 4 \end{bmatrix} \]
- This operation extracts features such as edges, textures, and patterns in images and is fundamental in deep learning for tasks like image recognition, object detection, and segmentation.

{kind=link}
{kind=link}
댓글
댓글 쓰기